파이썬을 기반으로 car_crashes 데이터 분석을 연습해보자. import pandas as pd import seaborn as sns import numpy as np 우선, 판다스와 시본, 넘파이 모듈을 불러온다. df = sns.load_dataset('car_crashes') 구글링을 하던 중! car_crashes 라는 재미있어보이는 데이터 셋 발견!
load_dataset 함수를 이용해 데이터를 불러와보자. 데이터가 꽤나 재미있어 보인다. row와 column은 각각 몇줄 정도일까?
51행, 8컬럼이다. 그렇게 큰 데이터셋은 아니다.
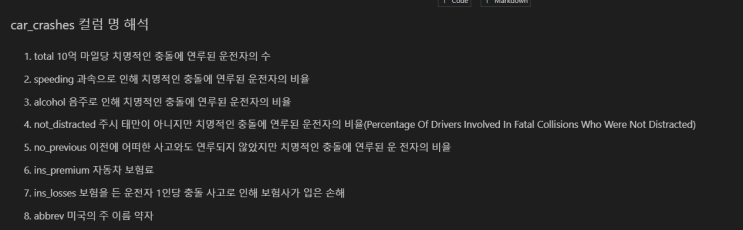
컬럼명을 또 정리해보았다. query 구문 연습을 해보자. abbrev가 'AR'인 레코드들의 평균을 한 번 출력해보자! df.query("abbrev == 'AR'").alcohol.mean() 5.824가 나온다.
참고로, #1번 구문과 2번 구문은 같은 결괏값을 도출함. df.alcohol.mean() df.loc[:, 'alcoh...
#
bdaa
#
파이썬
#
시본
#
빅데이터
#
데이터테이블
#
데이터시각화
#
데이터사이언티스트
#
데이터공부
#
데이터
#
넘파이
#
vscode
#
seaborn
#
python
#
pandas
#
numpy
#
dataanalytics
#
data
#
bigdata
#
판다스
원문 링크 : 파이썬 car_crashes 데이터 분석