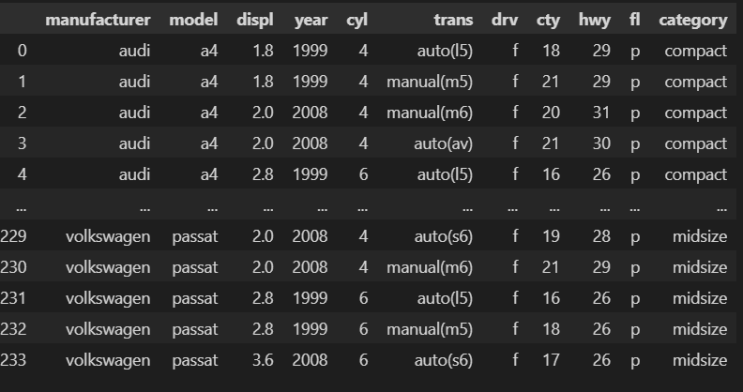
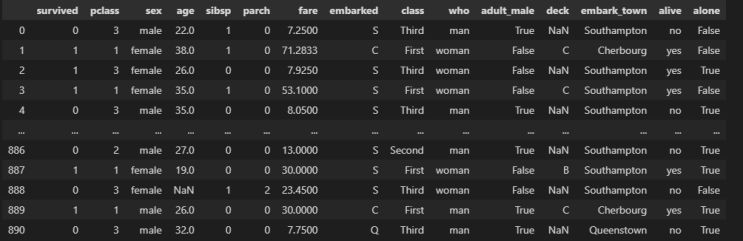
그동안 좀 다른일로 바빠서, 포스팅이 좀 늦었다. 오늘은 seaborn의 타이타닉 데이터를 간단하게 원 핫 인코딩 하는 것에 대해 살펴보겠다. import pandas as pd import numpy as np import seaborn as sns 우선, 판다스와 넘파이, 시본을 불러온다. df = sns.load_dataset('titanic') df 시본에는 load_dataset 함수를 이용하여, titanic이라는 데이터를 불러올 수 있다.
자세한 내용은 이전 포스팅에서 살펴봤기에 스킵하겠다. 데이터 셋은 이렇게 생겼다. df.info() 컬럼들을 전체적으로 한 번 보자. deck에는 null값이 좀 많아보인다.
보통 null값이 70% 미만이면 삭제처리 한다고 하니 deck은 컬럼을 삭제해도 나쁘지 않아보인다. 다만, 오늘은 간단하게 원 핫 인코딩 복습정도로만 할 예정이니, 일단 내비두자.
원 핫 인코딩이 무엇일까? "원-핫 인코딩(One-Hot Encoding)은 여러...
#
bdaa
#
데이터
#
데이터분석
#
머신러닝
#
브다
#
사키잇런
#
시본
#
원핫인코딩
#
타이타닉
#
파이썬
#
넘파이
#
vscode
#
titanic
#
bigdata
#
data
#
machinelearning
#
numpy
#
onehotencoding
#
pandas
#
python
#
scikitlearn
#
seaborn
#
판다스
원문 링크 : 타이타닉 머신러닝 사전준비(원 핫 인코딩)