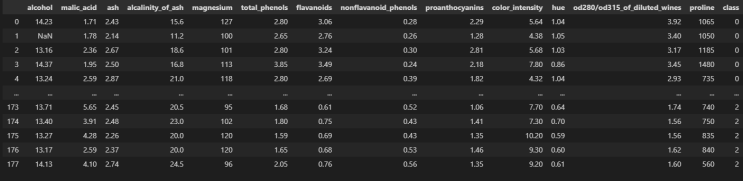
BDA에서 내준 wine_test의 정확도를 예측하는 코드를 공부해보자. standard, minmax, robust 알고리즘을 활용하여 정확도를 예측해보자 우선, 스케일링이란, 모델이 잘 작동할 수 있도록 데이터셋의 모든 특성이 분포를 같게 만들어 주는 것을 의미한다. 예로, 대학생의 키와 몸무게를 비교하려 할때, 키와 몸무게는 단위와 평균 모두 다르다.
따라서, 비교하기 위해서는 분포를 같게 만들어줄 필요가 있는데 이처럼 데이터셋에서 분포를 같게 만들어주는 작업을 스케일링 이라 한다. standard 알고리즘 데이터의 평균 = 0, 분산은 = 1이 되도록 스케일링 하는 방법이며, 정규분포로 만든다고 생각하면 된다. 이는 데이터의 최대치와 최소치를 모를때 사용되며 이상치에 영향을 받는다. minmax 알고리즘 데이터가 0과 1 사이에 위치하도록 스케일링하는 방법이다.
각 변수가 정규분포가 아니거나 표준편차가 적을때 효과적인 방법이다. robust 알고리즘 데이터의 중앙값 = 0, ...
#
BDA
#
빅데이터분석학회
#
빅데이터
#
비디에이
#
브다
#
머신러닝
#
마케팅
#
마케터
#
데이터분석
#
데이터
#
과제
#
KNN
#
data
#
bigdata
#
BDAA
#
알고리즘