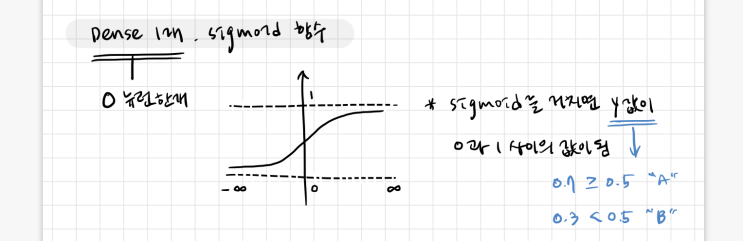
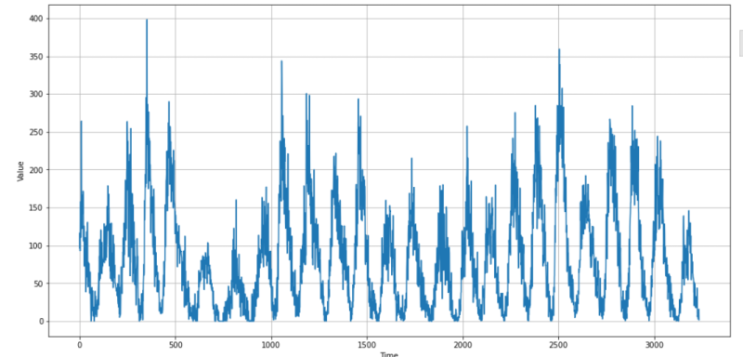
sunspots.csv를 사용하여 시계열 데이터를 예측하는 모델을 만들어 보려고 한다. sunspots.csv는 태양의 흑점 활동 데이터인데, csv로 제공되기 때문에 필요한 데이터들을 csv.reader()를 이용해 가져온다. with open('sunspots.csv') as csvfile: reader = csv.reader(csvfile, delimiter=',') next(reader) # header skip for row in reader: suspots.append(float(row[2])) time_step.append(int(row[0])) 리스트로 만들어진 sunspots와 time_step 데이터는 모델에서 받아들이지 못하기 때문에 numpy array로 변환해 사용해야 한다. 흑점 데이터가 삼천 개가 조금 넘는 걸로 알고 있는데, 인덱스 3000을 기준으로 train, validation set을 나눠서 사용할 것이다. time_train = time[:spl...
#
HuberLoss
#
머신러닝
#
분류모델
#
시계열
#
시계열데이터
#
시계열데이터예측
#
시계열예측
#
케라스
#
태양흑점데이터
#
딥러닝분류모델
#
딥러닝분류
#
keras
#
LSTM
#
rnn
#
SGD
#
sunspots
#
딥러닝
#
딥러닝rnn
#
딥러닝기초
#
흑점데이터