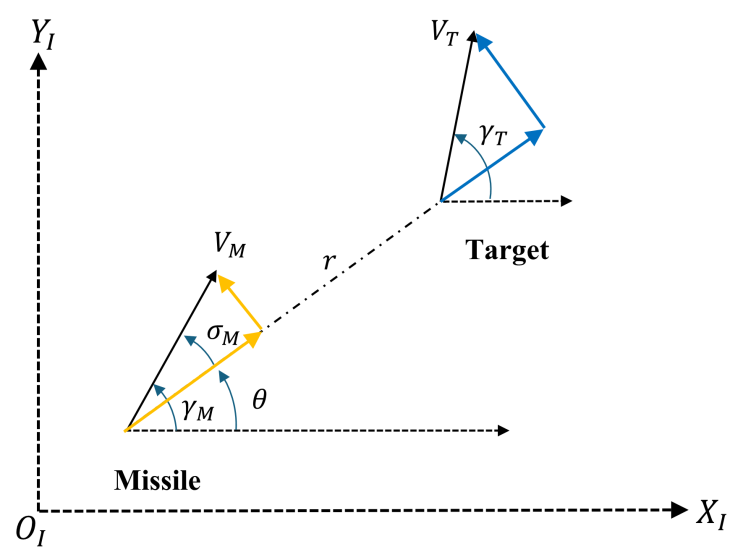
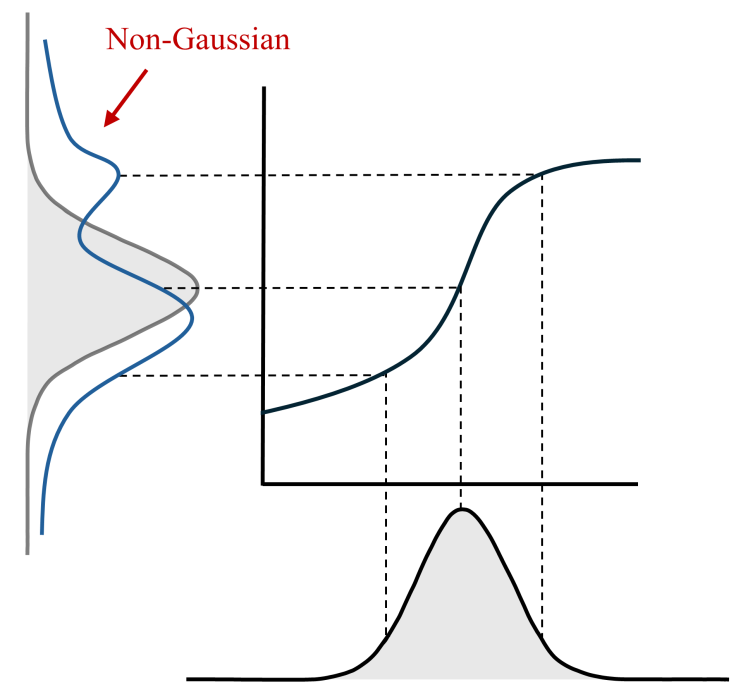
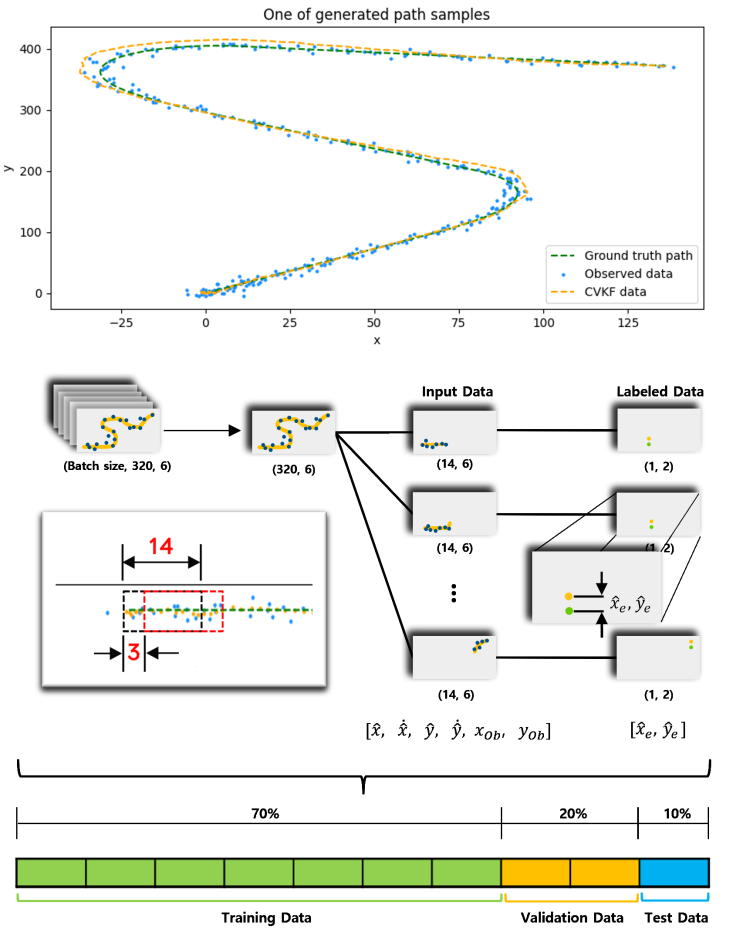
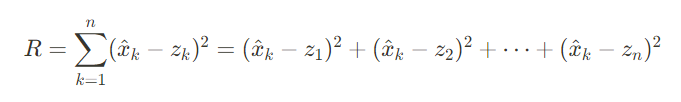칼만 필터의 Q 행렬을 에이전트 액션으로 예측하여, 추정 성능 개선을 목표로 한다. 따라서 연속적인 액션에 적합한 DDPG를 사용하기로 하였다.
우선 DDPG가 왜 연속적인 액션에 적합한지 알기 위해서 확률적 정책과 결정론적 정책에 대한 이해가 필요하다. 확률적 정책, 결정론적 정책 정책(Policy, π)는 에이전트가 주어진 상태에서 어떤 행동을 선택할지를 결정하는 함수이고, 크게 두 가지로 나뉜다.
확률적 정책(Stochastic Policy): 특정 상태에서 행동을 확률적으로 선택 결정론적 정책(Deterministic Policy): 특정 상태에서 항상 같은 행동을 선택 여기서, a는 행동, s 는 상태, θ 는 정책 네트워크의 파라미터이고, DDPG는 결정론적 정책 네트워크를 사용한다. 결정론적 정책을 업데이트하기 위해 결정론적 정책 기울기(Deterministic Policy Gradient, DPG)를 사용하고 다음과 같이 정의된다.
여기서, J (θ)는 목표 함수(보상...
![[강화학습 - 3] 결정론적 정책 기울기 Deep Deterministic Policy Gradient, DDPG](https://blogimgs.pstatic.net/nblog/mylog/post/og_default_image_160610.png)
#
Deterministic
#
reinforcelearning
#
RL
#
강화학습
#
결정론적정책