파이썬의 판다스 기반 가장 유명한 타이타닉 데이터 분석하는 연습을 해보겠다. import pandas as pd import numpy as np import seaborn as sns 우선, 판다스와 넘파이 및 seaborn 모듈을 불러온다. seaborn 모듈은 데이터 시각화를 하기 위한 모듈이다. #타이타닉 데이터 불러오기!
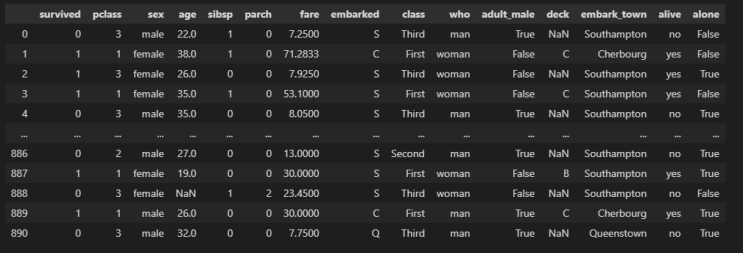
df = sns.load_dataset(('titanic')) seaborn 내에 load_dataset 함수를 이용해서 가장 유명한 titanic 데이터를 불러온다. df 데이터를 한 번 살펴보자. 언뜻 보면 비슷해보이는 컬럼들이 많다.
내가 원하는 컬럼들만 이용해서 데이터 분석을 해보자. 이건 내가 찾아보면서 정리한 컬럼명들이다.
확실히 겹치는 부분들이 있다. 그럼, 필요없어보이는 컬럼들을 삭제해보자. df.drop(columns=['sibsp', 'parch', 'embarked', 'class', 'adult_male', 'embark_town', ...
#
code
#
파이썬
#
타이타닉
#
코딩
#
캐글
#
마케팅
#
데이터사이언티스트
#
데이터분석
#
데이터
#
공부
#
seaborn
#
python
#
pandas
#
numpy
#
data
#
판다스
원문 링크 : 파이썬 판다스 타이타닉 데이터 분석 연습