첨부파일 train.csv 파일 다운로드 파이썬 판다스로 train데이터 분석을 해보자. 우선, train 데이터를 불러오기 전 필요한 것들을 임포트한다. import pandas as pd 그 후, train 데이터 불러오고 index_col=0 구문을 통해, index를 0번째 컬럼으로 지정한다. train = pd.read_csv('C:/Users/User/workspace/BDAA/data/train.csv', index_col=0) train 이후 출력!
굉장히 데이터가 많다. 이 데이터는 약 26,000개의 로우와 19개의 컬럼이 존재한다!
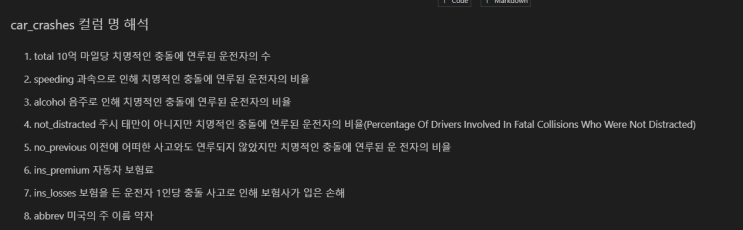
컬럼들에 대한 설명은 학회장님께서 공유해주셔서 어렵지 않게 컬럼들에 대해 이해하였다. index gender: 성별 car: 차량 소유 여부 reality: 부동산 소유 여부 child_num: 자녀 수 income_total: 연간 소득 income_type: 소득 분류 ['Commercial as...
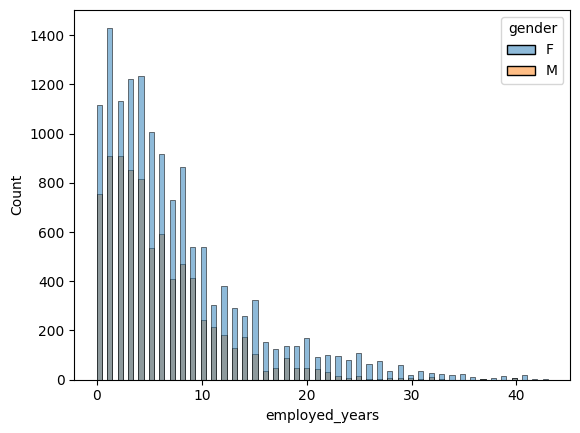
#
bda
#
시본
#
코드
#
코딩
#
데이터애널리틱스
#
데이터시각화
#
데이터분석
#
데이터
#
train
#
seaborn
#
python
#
파이썬
#
pandas
#
data
#
판다스
#
bdaa
#
시각화
#
조건부확률
#
빅데이터분석학회
#
빅데이터
#
브다
#
박스플롯
#
바플롯
#
plot
#
bigdata
#
확률
원문 링크 : 판다스 train 데이터 분석과 시각화