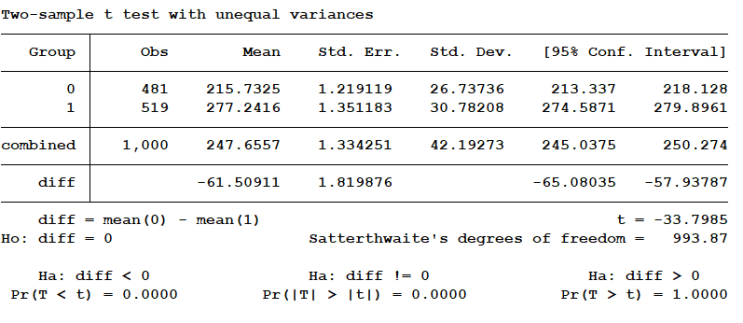
이번에는 R을 활용하여 R의 xtabs()함수 및 aggregate()함수를 조합하여 분할표와 각 셀에 대응하는 제3의 변수의 평균을 활용해 보도록한다. 논문통계분석이나 보고서 등에 자주 사용된다.
본 글에서 예제자료는 인터넷에서 제공되는 Stata파일을 이용한다. RStudio에 자료를 불러오기 위해서는 아래와 같이 입력하면 된다.
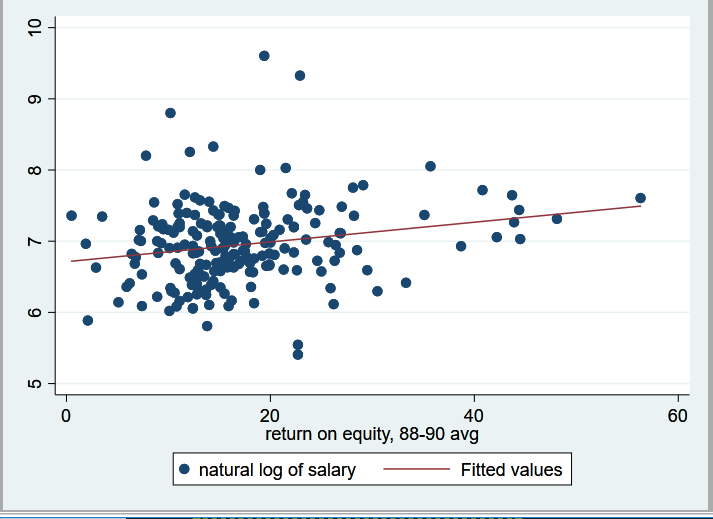
<그림 1>과 같은 결과를 확인할 수 있다. 자료를 불러온 뒤에 기본적인 자료를 파악해보도록 한다. library(readstata13) example<-read.dta13("http://www.stata-press.com/data/r15/sysdsn1.dta") str(example) <그림 1> 본 예제에서 사용할 명목형 변수는 male와 nonwhite이다.
두 변수 모두 0과 1의 값을 취하는 변수이다. 다음과 같이 두 변수에 대하여 교차표를 만든뒤에 각셀에 절대 빈도를 확인해 보도록 하자. > table(example$male, example$...
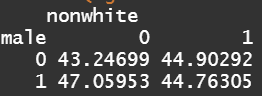
#
aggregate
#
narm
#
R
#
RStudio
#
tapply
#
with
#
xtabs
#
논문통계분석
원문 링크 : 논문통계분석 분할표와 평균 R활용