
자연어 처리(NLP)나 정보 추출을 하다 보면 이런 생각이 들죠. "단어 하나만 보면 판단하기 어렵다.
주변 단어를 함께 봐야 제대로 이해할 수 있지!" 바로 그런 문제를 다루는 모델이 있습니다.
오늘의 주인공은 Conditional Random Field (CRF) 입니다. CRF란?
Conditional Random Field는 조건부 확률 모델입니다. 입력(문맥 등)이 주어졌을 때, 레이블 시퀀스 전체의 확률을 모델링합니다.
예: "나는 학교에 간다" → 나는/NP 학교/NP 에/J 간다/V 여기서 단어별로 품사를 예측할 때, 단어 하나씩 예측하는 게 아니라 전체 문장의 품사 시퀀스를 함께 고려합니다. 왜 CRF가 필요할까?
문제: 독립적인 예측의 한계 기존의 로지스틱 회귀 등은 각 단어마다 독립적으로 라벨을 예측합니다. 하지만 실제로는 이전 단어의 품사가 현재 단어의 품사에 큰 영향을 미칩니다.
예: "은"은 체언(명사) 뒤에 올 가능성이 높습니다. 즉, "은"의 품사를 ...
![[머신러닝] Conditional Random Field – 문맥을 읽는 예측의 기술](https://mblogthumb-phinf.pstatic.net/MjAyNTA3MDRfMjI4/MDAxNzUxNjExNjUwNjM4.7jA-3eI9JgH88oZjEFqIMNGFiF2rZov2K2kSElLWdOIg.edXMkg-zBnJgpZk5CPp9-NshuhuNAIkW9jWI7L5qNgUg.PNG/image.png?type=w2)
![[안드로이드] CheckBox 사용](https://blogimgs.pstatic.net/nblog/mylog/post/og_default_image_160610.png)
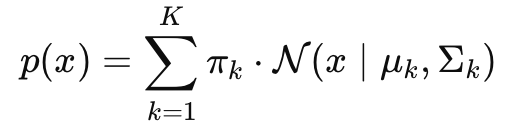
![[머신러닝] Energy Based Model – 에너지가 낮을수록 가능성은 높다?](https://mblogthumb-phinf.pstatic.net/MjAyNTA3MDRfMTkw/MDAxNzUxNjE0MzExODcy.Hh7kQFWawdrqWlLtvL-w2DPkwqUj5_9TXaB_kauzp2Mg.A33gGOn9LrDWTtRpnB5A-ng2dlamnvznJS-NpmbtpKog.PNG/image.png?type=w2)