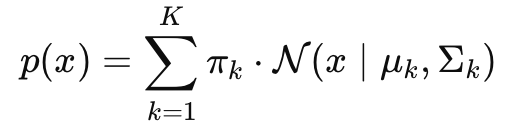첨부파일 gmm_em논문-zip.axx 파일 다운로드 데이터 분석에서 "데이터가 어디에 속하는지 모를 때", 우리는 종종 데이터를 확률적으로 설명하려는 시도를 합니다. 그 대표적인 모델이 바로 GMM(Gaussian Mixture Model)이고, 이를 학습시키기 위한 핵심 기법이 EM(Expectation-Maximization) 알고리즘입니다.
GMM(Gaussian Mixture Model)이란? GMM은 말 그대로 여러 개의 가우시안(Gaussian, 정규분포)을 섞어서 만든 모델입니다.
"우리 데이터는 단일 분포가 아닌, 여러 개의 정규분포로 구성되어 있다"는 가정하에 모델링하죠. 예를 들어, 사람의 키를 생각해보면 남성과 여성 각각은 정규분포를 따르지만, 전체는 두 개의 분포가 섞인 모양이 됩니다.
이걸 수학적으로 표현하면: K: 혼합할 가우시안의 개수 (클러스터 개수처럼) πk: 각 가우시안의 가중치 (전체에서 차지하는 비율) N(x∣μk,Σk): 평균 μk, 공분산 ...