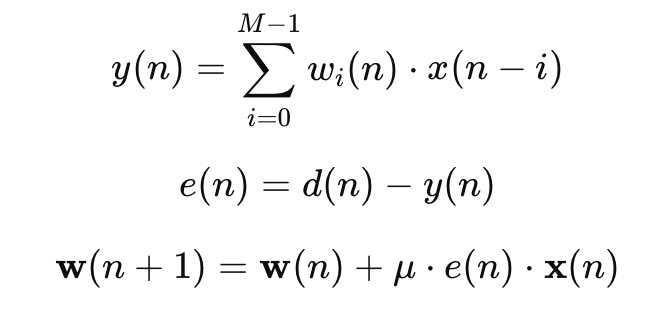첨부파일 k_means-zip.axx 파일 다운로드 K-means는 데이터 과학이나 인공지능을 공부하다 보면 초반에 꼭 만나게 되는 알고리즘 중 하나입니다. 특히 "비슷한 데이터를 묶고 싶을 때", 가장 많이 사용되는 군집화(Clustering) 기법이죠.
K-means란? K-means는 주어진 데이터를 K개의 그룹(클러스터)으로 자동으로 나누는 알고리즘입니다.
"비슷한 것들끼리 묶자!"는 간단한 생각에서 출발했지만, 실제로는 놀랄 만큼 다양한 분야에서 쓰이고 있어요.
예를 들어, 고객을 소비 패턴에 따라 분류할 때 이미지를 색상별로 압축할 때 뉴스 기사를 주제별로 나눌 때 음성 신호의 특징을 군집화할 때 등등… 응용 범위는 매우 넓습니다. 저는 GMM의 EM 알고리즘의 초기 상태를 설정하기 위해 사용했습니다. ️
어떻게 작동할까? K-means는 아주 단순한 방식으로 동작합니다.
'임의로 중심을 잡고 → 데이터를 할당하고 → 중심을 다시 계산하고 → 반복'합니다. 작동 순서 ...
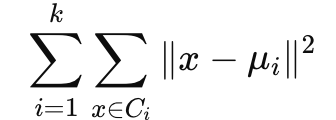
원문 링크 : K-means 알고리즘, 군집화의 시작점
![음성신호처리 -4- QCELP 기초 [o]](https://blogimgs.pstatic.net/nblog/mylog/post/og_default_image_160610.png)
![[음성 신호 처리 - 기초 9] LSP (Line Spectral Pair)](https://mblogthumb-phinf.pstatic.net/MjAxOTEwMDZfMTAw/MDAxNTcwMzYxMTg3MDY5.0yBrqqG4cK1Tpu5_dkscQwc8N2j9supHoM2ORmBUYgog.6HG-XoL7HuvzGj03RHXgGjaiQ9R-r-h4bghGdv2gB08g.PNG.gaechuni/image.png?type=w2)