else 관련 실수로 break가 존재해도 반복이 끝나지 않는 경우나 continue가 있어도 else가 실행되는 현상, 반복이 한 번도 실행되지 않아도 else가 실행되는 경우를 지적한다. 또한 else 안에서 break를 쓸 수 있다고 오해하지만 이를 악용하면 불필요하게 코드가 복잡해진다고 설명한다. 핵심은 break가 가장 가까운 반복문을 즉시 종료하고, continue는 현재 반복만 건너뛴 채 다음 반복으로 넘어가며, for/while-else는 break 없이 반복이 정상 종료되었을 때만 실행된다는 원리다.
파이썬 고급 반복 구조와 Iterator 사용에서 나타나는 실수 유형은 다양하다. Iterator의 핵심 원리는 Iterable→iter()→Iterator→next()로 데이터가 한 방향으로 소비되어 끝나면 StopIteration이 발생한다는 점이며, 한 번 소비하면 재사용 불가가 일반적이다. 대표적인 실수로는 Iterable과 Iterator의 혼동, Iterator나 Generator의 재사용 오해, next()의 남용으로 인한 StopIteration 위험, for문과 next()의 혼용으로 이미 소비된 값 출력 문제, list() 변환의 재사용 문제, 길이 인덱싱의 잘못된 기대 등이 있다. 또한 Generator와 Generator Expression의 차이, yield와 return의 구분, yield from의 올바른 해석, 무한 Iterator의 종료 조건 필요성까지 다룬다. 마지막으로 Iterator와 Iterable 구분, 재사용 여부, 불필요한 변환 회피, 무한 반복의 종료 조건 확보가 핵심 체크포인트로 제시된다.
파이썬 고급 반복문 설계와 성능 최적화는 반복문의 구조를 어떻게 설계하느냐가 성능에 큰 영향을 준다고 본다. 반복문 구조 설계에서는 컴프리헨션의 활용으로 코드를 짧고 효율적으로 만들고, 중첩 반복문의 남용을 피하는 것이 중요하다. 시간 복잡도 측면은 리스트 검색을 세트로 바꾸고 O(n²)에서 O(n)으로 개선하는 식으로 최적화를 고려하며, 데이터 규모에 따라 실행 속도가 달라진다는 점을 명시한다. 메모리 사용 측면에서는 리스트 생성 대신 제너레이터를 활용하고, 불필요한 중간 결과 저장을 금지한다. 불필요한 연산은 중복 계산 제거, deepcopy, 정렬, 형변환 등을 자제하고 문자열 처리에서는 += 대신 join을 권장한다. 조건문 설계, 객체 생성 비용, 병렬 처리의 활용, 성능 측정과 프로파일링의 중요성도 강조된다. 마지막으로 반복문 설계의 핵심은 반복 횟수를 줄이고 불필요한 연산과 메모리 사용을 최소화하며 필요한 순간에 데이터를 효율적으로 처리하는 구조를 설계하는 것이라고 요약한다.
파이썬 반복문의 구조적 한계는 반복문의 본질적 특성에 기인한다. 순차 실행과 단일 처리, 이전 반복으로의 자동 복귀 불가, 미래 반복 선실행 불가, 무작위 접근 불가, 상태 저장의 자동 부재 등은 외부 이벤트 기반 구조와의 차이를 만든다. 성능과 유지보수의 한계로는 중첩 반복문의 복잡도 증가, 가독성 저하, 종료 조건 관리의 어려움, 확장성의 한계가 지적된다. 외부 요인으로 외부 상태 의존, 대용량 데이터에서의 확장성 문제도 남는다. 결론은 반복문은 강력하지만 순차적·단일 처리 구조라는 본질적 한계가 있어 대규모 데이터나 병렬 처리, 이벤트 기반 프로그램에는 다른 구조와 함께 설계하는 것이 필수적이라는 점이다.
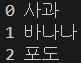
#
enumerate
#
파이썬심화
#
파이썬성능
#
파이썬반복문
#
파이썬
#
코딩공부
#
zip
#
Python
#
Iterator
#
파이썬에러