
패널 데이터는 같은 값에 대해서 두번 이상 측정된 것을 의미한다. 당연히 기존의 OLS방식과는 다른 방식으로 데이터를 분석하게 된다.
왜 패널 데이터를 사용하는가? library(palmerpenguins) library(ggplot2) pengs<-penguins names(pengs) <- c("sp" ,"is", "bl", "bd", "fl" ,"bm" ,"sx", "yr") 먼저 데이터를 불러와보자.
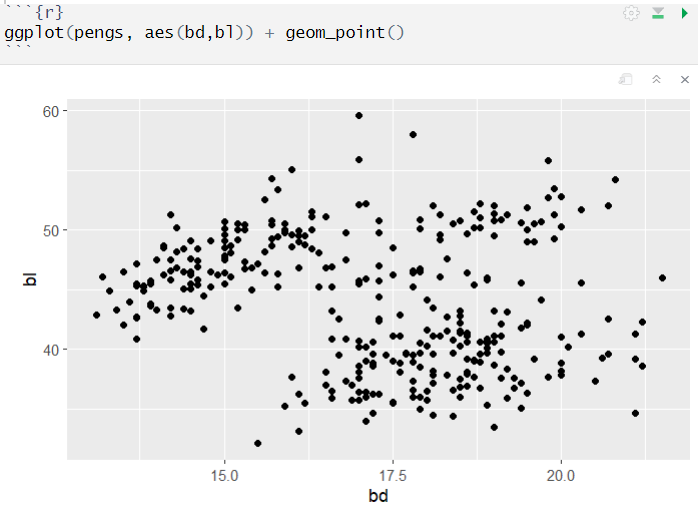
그리고 나서 x축에 bd, y축에 bl을 넣으면 위와 같은 산점도를 볼 수 있다. 굳이 회귀 선을 그어보면 위와 같이 음의 기울기가 나온다.
하지만 종을 기준으로 선을 따로 그으면 위와 같이 양의 기울기가 나온다. 즉, 데이터의 집단에 따라서 데이터 분석 결과가 아예 달라질 수 있고, 이로 인해서 패널 데이터 분석을 하는 것이다.
패널 데이터도 일종의 데이터 집단인 "시간"을 중심으로 데이터를 재분석 하는 것이며, 시간에 어떠한 소속이냐에 따라서 데이터를 분석하게 될 것이다. 기...
#
data
#
패널데이터
#
통계학
#
통계
#
최소제곱더미변수
#
첫번째차분
#
시계열데이터
#
고정효과모델
#
Pooled
#
POLS
#
panel
#
OLS
#
model
#
LSDV
#
fixed
#
First
#
effect
#
Difference
#
회귀분석
원문 링크 : 패널 데이터: 왜 사용하며 어떻게 사용하는가?
![[2023]러시아의 벨라루스 핵배치와 그 시사점](https://mblogthumb-phinf.pstatic.net/MjAyMzAzMzFfMjA4/MDAxNjgwMjI0ODk5MjI1.9ySvcuYJIIo5lq50wGYWHCYEfYPJTlL4d_sWdePLQLUg._L_kWJozhR-dfAmsZEU9_KurqFSYZyPPMqYqae3JBdQg.PNG.tornado720/image.png?type=w2)

![[의사결정론] 확률과 베이지안룰](https://mblogthumb-phinf.pstatic.net/MjAyNDAzMjlfMTI2/MDAxNzExNjkzOTEwMjI4.owRgzkIWF4Cwnk_lg3TN37M-b-0VrNn38mFCIFf4reMg.IXiCb2RZGSiFKZ7yHBDDyIn0f9TlBdHXilL1jl5TbzMg.PNG/image.png?type=w2)