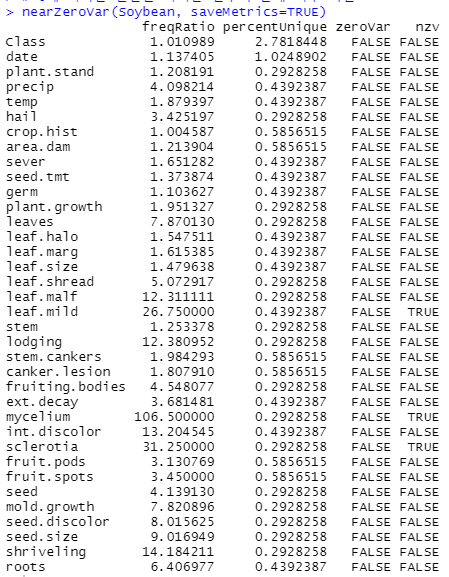
주성분 분석 2.0에 가까운 분산을 가지는 변수 제거 분산이 0에 가까운 변수는 제거해도 큰 영향이 없음 nearZeroVar()함수 where 'saveMetrics=FALSE'속성: 예측변수의 컬럼위치에 해당하는 정수 벡터 'saveMetrics=TRUE'속성: 컬럼을 가지는 데이터프레임 freqRatio: 가장 큰 공통값 대비 두번째 큰 공통값의 빈도의 비율 percentUnique: 데이터 전체로 부터 고유 데이터의 비율 zeroVar: 예측변수가 오직 한개의 특이값을 갖는지 여부에 대한 논리 벡터 nzv: 예측변수가 0에 가까운 분산예측 변수인지 여부에 대한 논리 벡터 install.packages("caret") library(caret) install.packages("mlbench") library(mlbench) nearZeroVar(iris, saveMetrics=TRUE) data(Soybean) head(Soybean) # 0에 가까운 분산을 가지는 변수의 존재...
#
0에가까운분산
#
chisquared
#
cor
#
findCorrelation
#
nearZeroVar
#
r
#
rstudio
원문 링크 : R : 변수제거
![python[프로그래머스] : 문자열 내 p와 y의 개수](https://blogimgs.pstatic.net/nblog/mylog/post/og_default_image_160610.png)