대학생의 견해가 들어가 있는 포스트입니다. 틀린 부분 있다면 언제든지 지적 부탁드립니다.
BM25 BM25는 Elastic Search와 같은 정보 검색 시스템에서 많이 사용되는 Rank Algorithm 중 하나이다. BM25는 TFIDF와 같이 Query와 Passage 간의 유사성을 측정하기 위해 단어의 출현 빈도를 고려한다.
Query와 Passage 간 일치하는 단어 수와 같은 요소 등을 고려하여 각 문서의 점수를 계산하며, BM25에서 사용하는 가중치는 단어가 Passage에서 출현하는 빈도와 Query에서 출현하는 빈도의 차이에 기반한다. 이해를 위해 BM25 수식을 살펴보도록 하자.
위 수식에서 c는 Document, c는 Query를 의미하며 ci 는 Query 내에 있는 Keyword를 의미한다. ※ 여기서 Keyword라는 것은 자연어 처리에서 Token을 의미한다고 생각하면 편할 것 같습니다. 또한 c1 과 c 는 Parameter이다.
보통 c1 ∈ [1.2,...
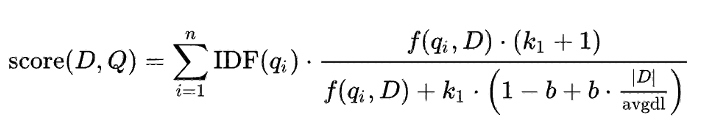
원문 링크 : (데이터 과학) BM25