논문 링크 : https://arxiv.org/pdf/2106.09685.pdf 개요 AI가 발전함에 따라 모델의 규모가 기하급수적으로 커지게 되었고, 더 이상 사용자 레벨에서 학습하기는 어려워지게 되었다. 때문에 언어모델(LM) 대부분의 파라미터를 freeze한 후 극히 일부분만 fine-tuning시키는 방법이 탄생하게 되었고, 이것을 PEFT라 부르게 되었다.
이 포스트에서는 PEFT 학습 방식 중 하나인 LoRA에 대해 알아보도록 하자. LoRA 이 방법은 특정 Task에 맞게 모델을 학습하는 과정에서 실제로 변화하는 가중치는 기존 모델보다 훨씬 낮은 Rank를 갖는다는 가정으로부터 시작되었다.
작은 가중치 변화만으로도 특정 Task를 잘 풀 수 있다면, 이를 별도로 분리해 별도의 matrix를 구성한 후 이를 fine-tuning하는 것이 모델 전체를 fine-tuning하는 것과 비슷하지 않을까? LoRA는 이런 가설을 기반으로 하여, 사전 학습 가중치는 freeze시킨 ...
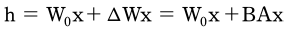
원문 링크 : (딥 러닝) LoRA : Low-Rank Adaption