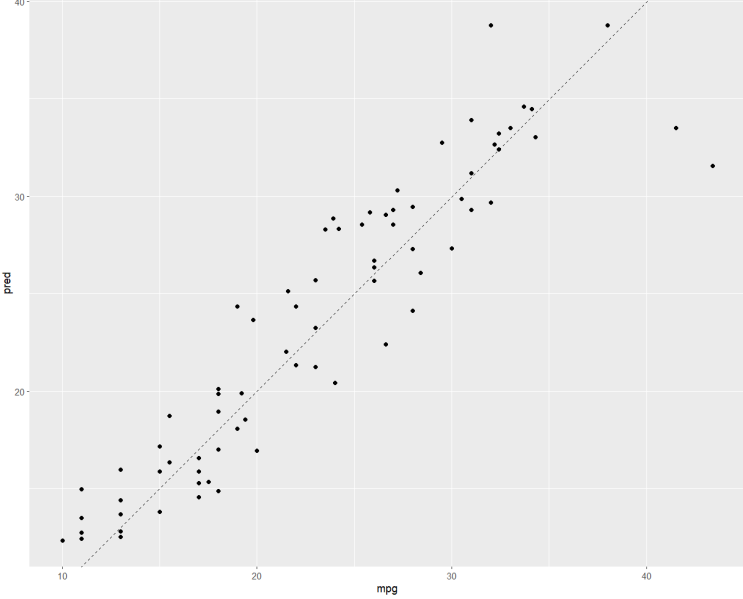
이번 포스팅에서는 k-평균 알고리즘을 이용하여 군집을 형성하는 방법을 배워볼 것이다. k-평균 군집분석(k-Means Clustering)이란? 주어진 데이터를 k개의 군집으로 묶는 알고리즘으로, 각 클러스터와 거리차이의 분산을 최소화 하는 방식으로 동작한다.
초기에 부적절한 병합이 일어났을 때 회복이 가능하며 군집의 수를 사전에 정의하고 대용량 자료의 경우 좋다. 알고리즘방식 1단계 - 원하는 군집의 개수 k를 사전에 결정하고 각 군집 중심을 임의로 설정 2단계 - 각 데이터를 그 중심과 가장 가까운 거리에 있는 군집에 할당 3단계 - 각 군집별로 단계2를 통해 할당된 개체를 이용해 군집중심을 재계산 4단계 - 단계2와 단계3의 과정을 모든 개체가 군집으로 할당될 때까지 반복 저번 포스팅에서 설명했던것 처럼 k-평균 알고리즘은 군집화를 위한 것이므로 분류를 하기위한 k-nn 알고리즘과 다르다.
즉, 정답 레이블이 없다. 데이터를 몇 개의 군집으로 나눌 것인지 결정해야하며 이것이 k...

원문 링크 : k-평균 알고리즘을 이용한 군집분석