
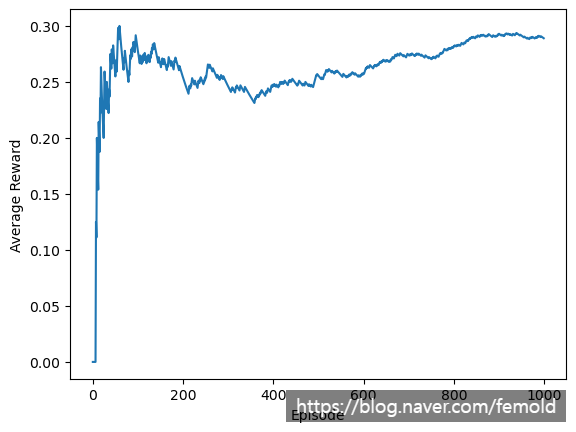
강화학습(reinforcement learning, RL) 설명을 위한 파이썬 소스코드 탐욕법(Greedy method)을 사용한 멀티 암드 밴딧(Multi-armed bandit) 문제를 다루는 간단한 강화학습 소스코드입니다. import numpy as np import matplotlib.pyplot as plt # 멀티 암드 밴딧 환경 class MultiArmedBandit: def __init__(self, num_arms): self.num_arms = num_arms self.probabilities = np.random.rand(num_arms) def pull(self, arm): return 1 if np.random.rand() < self.probabilities[arm] else 0 # 하이퍼 파라미터 num_arms = 10 num_episodes = 1000 # 환경 초기화 bandit = MultiArmedBandit(num_arms) # 평균 보상 초...
#
강화학습
#
학습
#
자율주행
#
자연어처리
#
인공지능
#
의사결정
#
환경
#
알고리즘
#
시간
#
비용
#
경험
#
보상
#
게임
#
로봇제어
#
머신러닝
#
전략
#
점수
#
최적의액션
#
최적화
#
학습자
#
승리
#
기술
#
인공지능분야
#
인공지능기술
#
응용
#
문제점
#
에이전트
#
발전
#
예측오류
![[Python 코딩] pygame을 이용해 간단한 창과 움직이는 사각형을 그리는 코드](https://mblogthumb-phinf.pstatic.net/MjAyMzAyMTVfMTUy/MDAxNjc2NDY3MDA2MDkz.cU9lXKjLXiZ9_nzZXJpqyeDJ8gy_UpgeIaTHhneR2KQg.1dpts9xvxEYKo5IT635nERRa2UfLyqD4sA6VB8egH00g.PNG.femold/image.png?type=w2)



