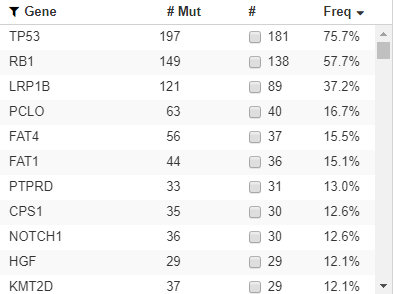
PCA 계산 방법 연속 초기 변수의 범위 표준화 상관 관계를 식별하기 위한 공분산 행렬 계산 공분산 행렬의 고유 벡터와 고유 값을 계산하여 주성분을 식별 유지할 주성분을 결정하기 위해 특징 백터 구축 주성분 축을 따라 데이터 재구성 Step1. 표준화(Standardization) PCA를 진행하기 위해 표준화를 진행하는 이유는, 초기 변수의 분산에 민감하게 반응하기 때문인데, 초기변수의 범위 차이가 크다면, 넓은 범위에 존재하는 변수들은 대부분 좁은 범위에 존재하고, 이는 편차(bias)가 생긴 결과를 가져온다(0~100이라면, 대부분 0,1 사이에 존재함).
수학적으로는 z-score 를 사용하거나 log 값을 취하는 방법으로 표준화를 진행한다. #/bin/Rscript #log, N is number log(A, base=N) #Z-statistic qnorm(A) Step 2.
공분산 행렬 계산 변수들이 서로에 대해 평균과 얼마나 차이가 있는지, 어떤 관계가 있는지 확인하는 ...

원문 링크 : GWAS)PCA 계산 방법(1)