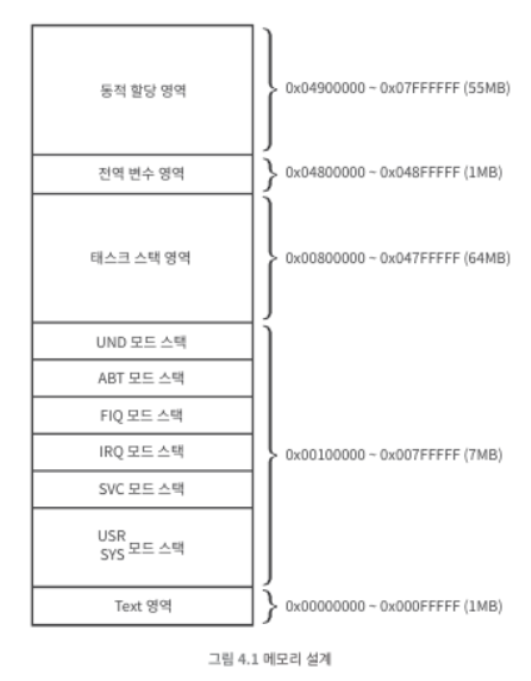
1. SGD(확률경사하강법)실행 SGD를 실행했을 때 매우 큰 메모리가 소모된다.
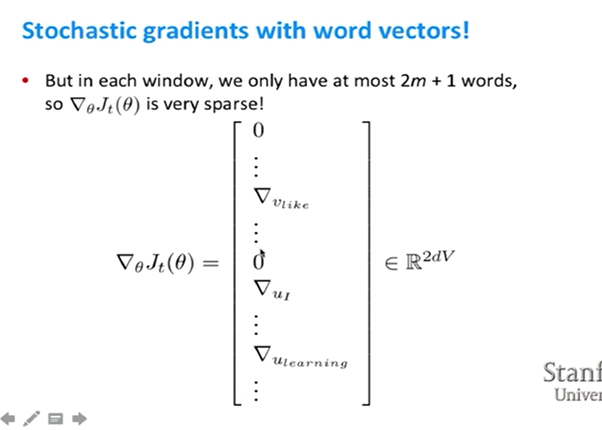
Solution: 특정한 Columns만 업데이트하는 희소 행렬 업데이트 연산을 필요로 하거나, Word 벡터에 대한 hash를 필요로 한다. 이때 value는 벡터이고 key는 word string이다. -> skip-gram모델에 대한 설명.
이때 우리가 이 모델을 계산할 때 위의 식에서 분자 부분은 계산이 간단하나, 분모 부분은 말뭉치가 이만개 있다고 가정한다면 계산을 이만번 해야 한다. 또한 각 윈도우에서 deep learning이나 learning은 zebra와 동시에 등장하지 않고 aardvark와도 동시에 등장하지 않는다.
왜냐하면 대부분의 단어들은 꽤 희소하기 때문이다. -> 진정한 쌍을 찾아서 이진 로지스틱 회귀를 하고싶다. 2. negative sampling *T는 말뭉치를 통과 할때의 윈도우에 해당한다. center word와 outsideword가 동시에 나타난다는 것을 의미한다...
![[C++] 백준 2606(인접 리스트, DFS)](https://mblogthumb-phinf.pstatic.net/MjAyMjExMTJfMTY5/MDAxNjY4MjMzMTc4MzIw.z3scOERBNX3ypf8xpd3Z8Y7drnDXNCdR-Hms954cjbMg.7GO0se1sBi8tinlAau1nQDMruR9t1XoqZPbPaHE-RXcg.PNG.gkswlcjs2/image.png?type=w2)

![[Java] 단순한 동전 챙기기](https://mblogthumb-phinf.pstatic.net/MjAyMzEwMDNfMTIx/MDAxNjk2Mjk3MDIwOTMx.OdA2E-cjIdTc8J6-knOii-2o77ZTX1rIdR4iUmVEhEsg.C6_5-9eqqCo9HhY02w9Ngu4JVqaHeThZ0FmC-Mw3argg.PNG.gkswlcjs2/image.png?type=w2)