2022 CVPR에 제출된 논문입니다. Transformer에 마스킹방법을 사용해서 Continual Learning을 진행하는 선두주자로서 소개되어집니다.
이전까지는 대부분 CNN에서의 뉴런에 대한 마스킹 방법을 사용했다면 이제는 Transformer의 개념을 활용하는 마스킹 방법들이 나오는 것 같습니다. 논문에 중점적으로 다루지는 않지만 배경으로 알아두면 좋은 것을 먼저 간단하게 정리하고 넘어가도록 하겠습니다.
사전 지식 1. Soft와 hard 머신러닝에서 흔히 사용되는 단어인 soft, hard는 의미하는 바가 동일합니다.
보통은 미분이 가능한 값으로 나타나면 soft, 미분이 불가능하게 딱딱 떨어지는 값으로 할당되면 hard라고 소개됩니다. 이에 대한 예시로써 soft label은 Softmax를 입힌 확률 값으로 볼 수 있고, hard label은 정확이 의미하는 인덱스 값 하나만을 나타내는 one hot encoding과 같은 값을 말합니다.
해당 단어는 지금 소개하는 ...
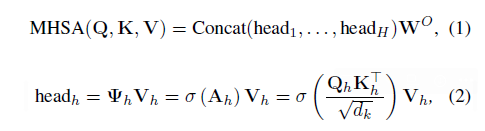
#
Attention
#
transformer
#
tokeninteraction
#
soft
#
selfAttention
#
self
#
MHSA
#
MEAT
#
mask
#
jjunsss
#
imagepattern
#
HAT
#
hard
#
gumblesoftmax
#
DEIT
#
CVPR
#
VIT