저자 : Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, Yong Jae Lee 학회 : CVPR 2023 논문 : https://arxiv.org/pdf/2301.07093.pdf 1. Introduction 기존의 텍스트-이미지 생성 모델은 텍스트만을 입력으로 사용하므로, 이미지의 특정 부분을 정확하게 제어하기 어렵습니다.
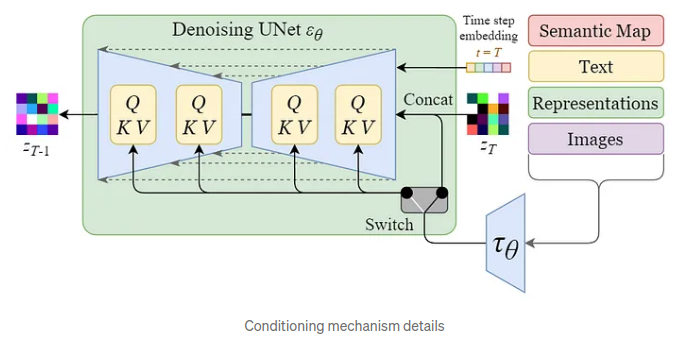
따라서 저자들은 바운딩 박스와 같은 그라운딩 정보를 추가로 사용하여 이미지 생성을 더욱 정확하게 제어할 수 있는 모델을 제안합니다. 기존에 훈련된 Stable Diffusion 모델의 가중치를 고정(freeze)하고 새로운 그라운딩 정보를 통합하는 새로운 계층을 추가함으로써 해당 모듈만 훈련하게 되는데, 이를 통해 새로운 공간 구성과 개념에도 잘 일반화되는 이미지를 생성할 수 있도록 유도합니다.
실제로 훈련은 추가된 모듈들만 따로 훈련됩니다. 제안...
#
attention
#
LDM
#
Openset
#
preserving
#
SA
#
Sampling
#
SD
#
Stable
#
StableDiffusion
#
디퓨전
#
생성모델
#
스테이블디퓨전
#
텍스트이미지생성
#
latentdiffusionmodels
#
latent
#
ImageGeneration
#
Bbox
#
conditioning
#
condittion
#
Diffusion
#
DiffusioncontinualLearning
#
diffusionmodels
#
gated
#
GatedSelfAttention
#
Generation
#
GLIGEN
#
Grounding
#
Image
#
프롬프트

![[2022 마이 블로그 리포트] 올해 활동 데이터로 알아보는 2022 나의 블로그 리듬](https://mblogthumb-phinf.pstatic.net/MjAyMjEyMTNfNiAg/MDAxNjcwOTE4NDcxODgz.fGo_Q_3y-2eAvlifarBxboxI2XSgaoIgj3I3ys5Wljog.1Nu1WKPGNI1fafdOThOUibYRMooXjt_4-zpNDAZrUjwg.PNG.jjunsss/my_blog_report.png?type=w2)