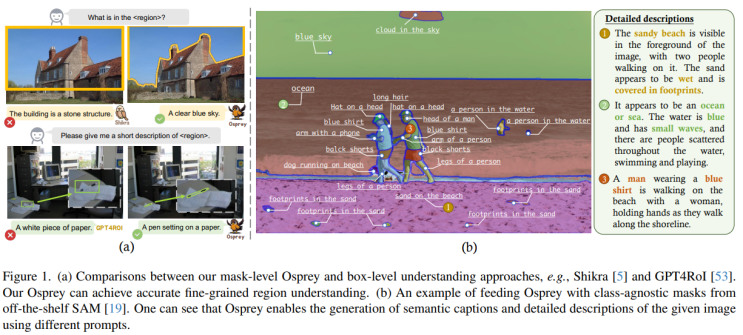
Abstract masked dataset 추가로 제안 ⇒ pixel-wise understanding 위해. design a vision-language model by injecting pixel-level representation into LLM CNN based CLIP for using as a image encoder and mask-aware visual extractor Applications; They use also with SAM for more semantic works. Introduction previous research limitation.
Region-level understanding에 국한되어 있는 연구들 언급. Kosmos-2 [37]: 이 연구는 bounding box를 지정된 영역으로 처리하고 객체 수준의 공간적 특징을 활용하는 시각적 지시 조정을 시도했습니다. [ https://github.com/microsoft/unilm/tree/mas...
#
AI
#
SOTA
#
Similarity
#
SentencesBERT
#
SAM
#
RegionLevel
#
PixelWise
#
Pixelunderstanding
#
Osprey
#
mLLM
#
InstructionFollowing
#
HQSAM
#
GPT4Gen
#
generative
#
explainable
#
Deeplearning
#
Dataset
#
BERT
#
VisualInstructionTuning