
0. 소개 안녕하세요.
현재 AI 분야를 평정하고 있는 생성형 AI(Generative AI)의 기본은 Self-Attention을 기반으로 하는 Transformer 구조입니다. Transformer는 지금까지 발표된 어떤 구조보다도 우수한 성능을 가지지만, 유일한 단점이라면 Model의 표현력과 비례해서 Hidden State도 커져야 한다는 것입니다.
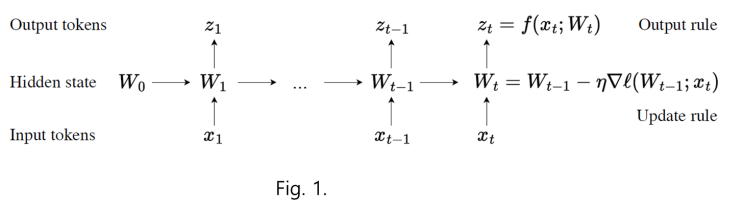
최근 발표된 Llama 3.1은 Model을 구성하는 Parameter의 개수가 4000억 개가 넘는다고 하죠. 이와 같은 Transformer의 구조는 한계를 극복하고자 발표된 Model이 TTT(Test-Time Training)이라는 구조로써, 핵심은 Hidden State 값들을 개별적으로 모두 저장하는 것이 아니라, Hidden State 값을 표현하는 Machine Learning Model을 만들고 이를 TTT(Test-Time Training) Layer라고 부릅니다.
이 TTT(Test-Time Training) ...
#
Backbone
#
State
#
Supervised
#
Test
#
Time
#
Training
#
Transformer
#
TTT
#
논문
#
논문리뷰
#
SelfAttention
#
Self
#
Expressive
#
GPU
#
Hidden
#
Learn
#
Linear
#
Llama
#
Mamba
#
nVidia
#
Perplexity
#
리뷰





