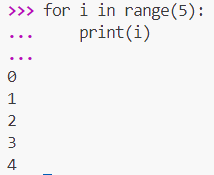
병렬 처리는 인풋을 받는 순간 동시에 여러 작업을 수행해 응대 속도를 높이는 아이디어에서 시작된다. 주문받는 사람, 커피 제조, 결제 같은 역할을 나눠 처리하면 한 명이 모든 일을 하는 경우보다 훨씬 빠르게 반응할 수 있다. 그러나 멀티스레드 환경에서 단순히 스레드를 늘리는 것이 항상 성능으로 이어지지는 않는다. 데이터 충돌이나 순서 꼬임, 예외 발생, 타이밍 이슈 등이 생겨 병렬 처리의 복잡성과 위험성도 체감된다. 기존에는 lock, Monitor, Mutex, Semaphore 같은 동기화 도구를 사용했지만 사용법이 복잡하고 실수 시 데드락이나 성능 저하가 발생한다는 점도 문제다. 초보자는 직접 락을 걸고 해제하는 과정에서 실수의 위험을 느끼며 심리적 장벽을 겪는다. 이로 인해 병렬 처리 방식은 Thread, ThreadPool의 고전 방식에서부터 Task, async/await의 일반적 방식, Parallel, PLINQ의 성능 최적화용 방식, Channel, TPL Dataflow, RX의 고급 API 등 다양한 형태로 구분된다. 스레드 간 데이터 전달은 공유 메모리 방식인 lock, Monitor과 데이터를 줄 세워 전달하는 메시지 큐 방식, 이벤트 발생 시 반응하는 이벤트 기반 방식으로 이뤄진다. 생산자-소비자 패턴은 데이터 생성 주체가 생산하고 이를 소비가 처리하는 구조로, 센서나 키보드 입력 같은 데이터 흐름을 안전하고 효율적으로 다룬다.
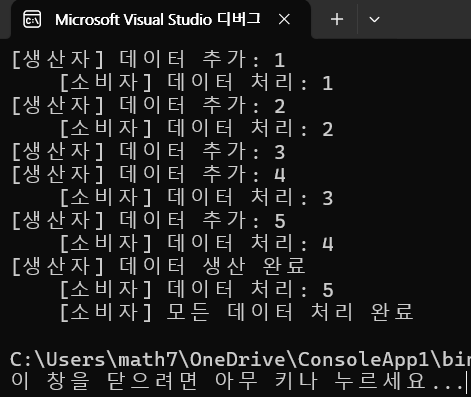
BlockingCollection의 정의와 용도는 먼저 이름의 의미를 이해하는 데 있다. Blocking은 필요에 따라 작업이 잠시 멈출 수 있음을 뜻하고 Collection은 여러 데이터를 담는 저장소이며 는 담을 데이터 타입을 가리킨다. 특정 타입의 데이터를 저장하는 컬렉션이면서 상황에 따라 자동으로 멈췄다가 다시 동작하는 특수한 구조다. 일반적인 컬렉션과의 차이는 동시 접근 시 충돌 위험이 있지만 BlockingCollection는 여러 스레드가 동시에 접근해도 안전하게 작동하는 스레드 안전 컬렉션이라는 점이다. Blocking의 의미는 비어 있을 때 데이터를 꺼내려 하면 자동으로 대기하고, 공간이 가득 차 있으면 자동으로 대기를 통해 넣으려 해도 즉시 오류가 나지 않는다는 점이다. 이 자동 대기 기능 때문에 스레드 간 통신이나 협업에 아주 적합하다. 생산자-소비자 시나리오에 최적화되어 한 스레드는 데이터를 생산하고 다른 스레드는 그 데이터를 꺼내 소비하는 구조를 안전하고 효율적으로 구현하도록 설계되어 있다. 내부 구조는 Concurrent 컬렉션을 기반으로 하며 보통 ConcurrentQueue를 사용해 FIFO를 따르되 필요 시 ConcurrentStack나 ConcurrentBag 등으로 교체 가능하다.
#
BlockingCollection
#
CSharp
#
CSharp동기화컬렉션
#
CSharp멀티스레드
#
CSharp병렬처리