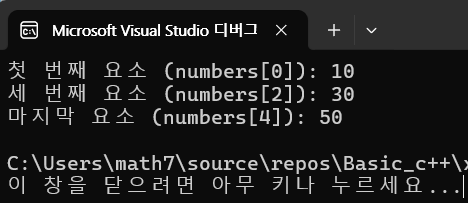
파이썬 반복문에서 자주 만나는 함수인 enumerate()와 zip()의 핵심 개념과 차이를 한눈에 정리한다. enumerate()는 반복 데이터에 번호를 붙여 주는 함수로, 예를 들어 fruits 리스트에 대해 list(enumerate(fruits))를 하면 [(0, "apple"), (1, "banana"), (2, "orange")]처럼 순서 정보가 부여된다. 필요한 이유는 특정 순서나 위치가 중요한 상황에서 번호를 함께 이용하기 위함이다. 반면 zip()는 여러 데이터를 같은 위치끼리 연결해 하나의 튜플로 묶어 주는 함수로, names 와 scores를 zip하면 각 이름과 점수가 짝지어진 형태로 얻을 수 있다. 이는 반복문에서 이름과 정보, 상품과 가격처럼 연결된 정보를 함께 다룰 때 유용하다.
두 함수의 공통점은 기존 데이터를 없애지 않고 새로운 형태로 변환한다는 점이다. enumerate()는 (번호, 값)의 형태로, zip()은 (값, 값) 형태로 묶는다. 차이점은 목적과 출력 형태다. enumerate()의 핵심은 순서를 부여하는 데이터 추가이며, zip()의 핵심은 서로 대응되는 데이터를 연결하는 것이다. enumerate()는 반복 가능한 객체에 대해 start 옵션으로 시작 숫자를 바꿀 수 있으며 반환은 enumerate 객체로, Iterator이므로 한 번 소비하면 재사용이 어렵다. 또한 향후에는 값 분해(Unpacking)로 (index, value)처럼 두 변수에 나눠 담는 형태가 일반적이다.
zip()은 여러 반복 가능한 객체를 같은 위치끼리 묶어 주며, 길이가 다른 시퀀스가 주어지면 가장 짧은 Iterable 기준으로 종료한다. 결과는 항상 튜플로 구성된 zip 객체이며, 필요 시 list나 dict로 변환 가능하다. Unpacking은 zip()와 함께 사용할 때 가독성을 크게 높이고, 중첩 unpacking이나 확장 unpacking도 가능하다. enumerate()와 zip()를 함께 쓰면 인덱스와 값의 쌍, 혹은 이름과 점수처럼 여러 정보를 한꺼번에 다루는 코드를 간결하게 작성할 수 있다.
또한 zip() 객체의 특징은 Lazy Evaluation으로 필요할 때만 새로운 튜플을 생성한다는 점이다. 두 함수 모두 원본 데이터를 직접 바꾸지 않으며, 반복 가능한 객체에서만 적용 가능하다. enumerate()의 start 옵션은 출력 번호를 바꾸는 것이지 실제 인덱스에는 영향을 주지 않는다. zip()의 길이 규칙은 가장 짧은 Iterable 기준으로 종료되며, 남은 데이터는 버려진다. 이 세 가지 원리를 이해하면 반복문과 데이터 처리에서 enumerate()와 zip()의 활용도가 크게 높아진다.

#
enumerate
#
파이썬사용법
#
파이썬반복문
#
파이썬기초
#
파이썬공부
#
파이썬zip
#
파이썬for문
#
파이썬enumerate
#
파이썬
#
코딩독학
#
개발공부
#
zip
#
PythonTutorial
#
Python
#
프로그래밍