문자 인코딩의 역사는 컴퓨터가 문자를 이해하게 만드는 규칙과 저장 방식의 발전으로 펼쳐진다. 컴퓨터는 문자 자체를 이해하지 못하고 전기 신호 0과 1로만 작동하므로 문자마다 고유한 숫자 코드가 부여되어야 한다. 문자 집합은 표현 가능한 글자들의 목록이며, 인코딩은 문자에서 숫자로, 다시 0과 1로 변환하는 과정을 말한다. 디코딩은 저장된 0과 1을 다시 문자로 바꾸는 과정이다.
ASCII 시대에는 영어 중심의 표준이 자리했다. 영문자, 숫자, 기호, 줄바꿈 문자 등을 7비트로 표현해 128개 문자를 다룰 수 있었지만 한글이나 한자 같은 추가 문자 표현은 불가능했다. 확장 ASCII가 등장해 8비트 체계로 128개를 더해 총 256문자를 표현할 수 있게 되었지만, 각 나라마다 추가 문자를 서로 다르게 재정의하면서 문자 깨짐 현상이 심화되었다. 한국어와 일본어 등은 같은 숫자라도 다른 문자로 해석되어 서로 다른 인코딩 체계가 생겨났고, 같은 파일을 다른 컴퓨터에서 열면 글자가 엉망이 되는 문제로 이어졌다.
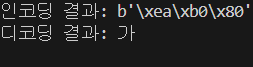
문제 해결의 방향은 전 세계 문자를 하나의 코드로 관리하는 Unicode의 탄생으로 이어졌다. Unicode는 모든 문자에 고유한 코드포인트를 부여해 전 세계 어디에서나 같은 문자가 같은 번호로 이해되도록 하는 국제 표준이다. 다만 코드포인트를 실제로 저장하거나 전송하려면 바이트로 표현하는 방식이 필요했고, 그 역할을 하는 것이 UTF 계열이다. UTF는 코드포인트를 0과 1로 이루어진 바이트로 바꾸는 변환 방식이다.
UTF의 주요 형식으로는 UTF-8, UTF-16, UTF-32가 있다. UTF-8은 1~4바이트의 가변 길이로 영어에 특히 효율적이고 ASCII와 완벽 호환되며 웹 표준으로 널리 사용된다. UTF-16은 2 또는 4바이트의 가변 길이로 다국어 처리에 유리하고 내부 처리에 효율적이지만 영어에는 비효율적이며 BOM(Byte Order Mark)이 필요하다. UTF-32는 고정 길이 4바이트로 단순하지만 메모리 낭비가 커 내부 시스템이나 특정 데이터베이스에서 주로 활용된다. 오늘날 웹과 운영체제, 프로그래밍 언어의 기본 인코딩으로 채택된 UTF-8 시대가 도래했고, 한글을 비롯한 모든 문자의 표현과 저장이 가능해졌다.
Unicode와 UTF의 관계는 서로 다른 역할이다. Unicode는 전 세계 모든 문자에 고유한 번호를 부여하는 규칙이고, UTF는 그 번호를 실제 데이터로 저장하거나 전달하기 위한 포장 방식이다. 이 구분은 문자 인코딩의 복잡한 구조를 이해하는 핵심이며, 영어 기반 시스템과의 호환성이나 다국어 지원의 효율성 측면에서도 결정적인 역할을 한다.
#
ASCII와UTF8차이
#
파이썬문자열인코딩원리
#
파이썬UTF8한글
#
코드포인트란
#
컴퓨터문자는어떻게저장될까
#
인코딩디코딩차이
#
유니코드란
#
문자인코딩종류
#
문자인코딩개념
#
문자깨짐원인
#
가변길이인코딩
#
UTF8작동원리
#
UTF8이란
#
UTF8바이트구조
#
파이썬문자인코딩