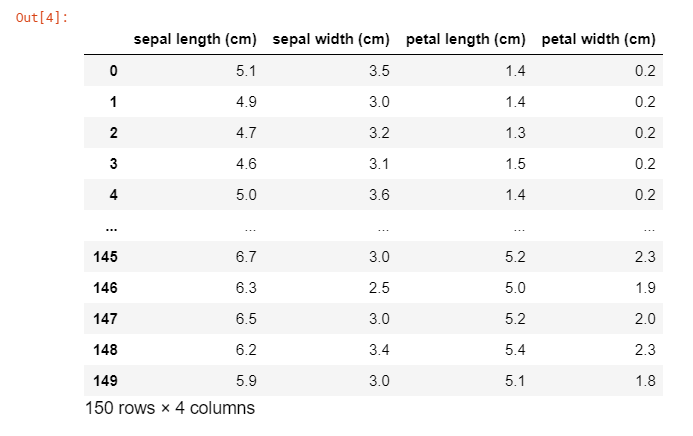
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier import pandas as pd iris_data = load_iris() # 데이터 셋 dataframe에 저장 X = pd.DataFrame(iris_data.data, columns = iris_data.feature_names) y = pd.DataFrame(iris_data.target, columns = ['class']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=5) y_train = y_train.values.ravel() model = RandomForestClassifier(n_estimators ...

#
sklearn
#
머신러닝
원문 링크 : sklearn 붓꽃 데이터셋 4. 랜덤 포레스트