이번에는 R을 활용하여, 논문통계나 보고서 등에서 자주 활용되는 두 개의 명목형 변수가 있고 이러한 변수에 각 값에 따라 혹은 교차 테이블의 각셀에 다른 연속형 변수의 평균을 구하는 작업을 해보도록 한다. 예제 자료의 경우 인터넷에서 Stata 자료를 받아서 이용하도록 한다.
R에 Stata의 자료를 불러오기 위하여 먼저 readstata13 패키지의 read.dta13() 함수를 이용해 보도록 한다. 자료를 불러온 뒤에는 간단하게 자료의 정보를 str()함수를 이용하여 살펴보도록 한다.
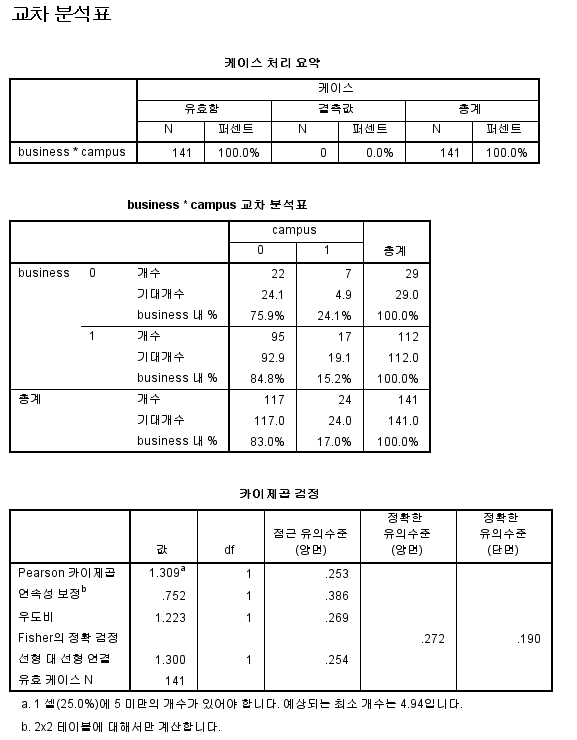
<그림 1>과 같은 결과를 확인하기 위해서 R에 아래와 같이 입력하면 된다. library(readstata13) article<-read.dta13("http://www.stata-press.com/data/r15/systolic.dta") str(article) <그림 1> 본 자료 파일에는 3개의 변수가 있는데 본 예제에서는 모두 활용하도록 한다. 여기서 명목형 변수는 drug과 disease...

#
pivottabler
#
qpvt
#
R
#
Stata
#
table
#
xtabs
#
교차표
#
논문통계
#
평균
원문 링크 : 논문통계 두 변수에 대한 교차표와 평균

![[R] 기술통계 psych패키지](https://mblogthumb-phinf.pstatic.net/MjAyMjAyMjFfNjAg/MDAxNjQ1NDMzMDM5MTEx.iSOXzvmm9HPmwgiiBHegJlRVrqX3__eMNArFgTVpicAg.UVqcqdki_EfhWRgivkU_XVodbsBU0OyZCt_QEU9jNOsg.PNG.ssuout/image.png?type=w2)