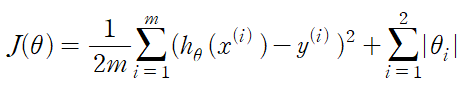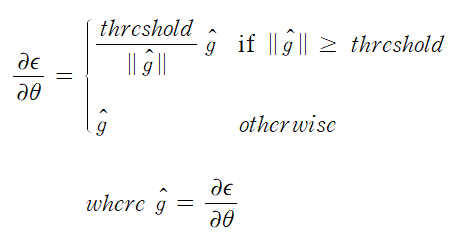개요 우리는 이전 포스트에서 모델 평가를 할 때 입력 변수와 목표 변수를 test 데이터와 training 데이터로 나누어 학습 시킨다는 것을 알고 있을 것이다. K겹 교차 검증은 전체 데이터를 K개로 나누어 순차적으로 test 데이터와 training 데이터로 나누어 학습시키는 방법을 의미한다.
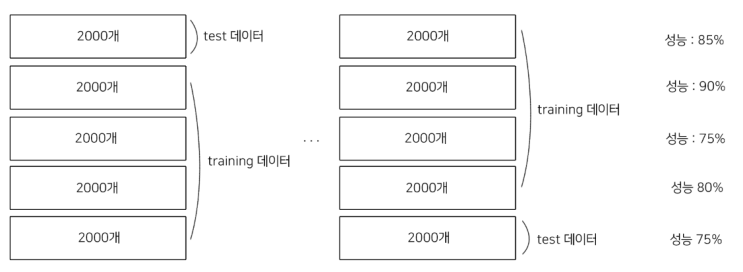
K겹 교차 검증 만약 10000개의 데이터가 있다고 하자. 그리고 K가 5 라고 한다면 10000개의 데이터를 2000개씩 5개의 묶음(set)으로 나누어 test 데이터와 training 데이터로 분류해서 학습시킨다.
그렇다면 위의 그림과 같이 총 5개의 test 데이터 묶음에 대한 성능이 있을 것이다. 이 5개의 성능에 대한 평균을 모델의 성능으로 보는 것이다.
성능 테스트를 여러번 수행함으로써 모델에 대한 신뢰도를 높이는 역할을 한다. K-겹 교차 검증 방법은 비교적 가용 데이터가 적고 가능한 정확하게 모델을 평가하고자 할 때 사용한다.
시간 복잡도는 O(P * K)가 되므로 여러 번...
원문 링크 : (머신 러닝) 모델 평가 / K-fold 교차 검증