DAPT와 TAPT 개요 Transformer의 발표 이후 여러가지 파생 모델이 세상 밖으로 쏟아지게 되었다. (BERT와 GPT가 대표적) 이런 모델들은 제각기 다른 모델 구조와 손실 함수를 가지고 있지만 한 가지는 동일하다.
바로 Pretraining 후에 fine tuning 하는 프레임워크이다. 사전 학습 시 대량의 Corpus를 학습하여 일반화 성능을 확보한 뒤, Downstream task에 대해 추가적인 학습을 진행하여 특정 Task에 맞춰준다는 개념은 동일했다는 것이다.
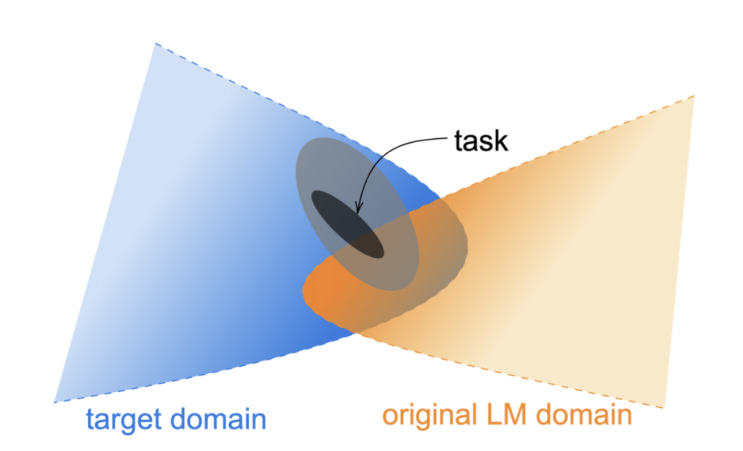
하지만 특정 도메인(의료, 금융 등)에서는 좋은 성능을 기대하기 어렵다고 한다. 일반적으로 Pretraining 시 사용하는 Wikipedia 데이터셋은 적용하고자 하는 데이터는 fine tuning할 때 쓸려는 데이터셋과는 도메인이 많이 다르기 때문이다.
그래서 다양한 방법으로 성능을 높여보려 노력하였고, 어느 순간 부터는 "도메인에 특화된 사전 학습이 필요하다"는 생각이 자리잡게 되었다고 한다. D...
원문 링크 : (자연어 처리) DAPT와 TAPT