개요 One-Hot 벡터로 단어를 표현하게 된다면 많은 문제가 발생한다. 그렇다면 좋은 방법은 없을까?
효과적으로 단어의 정보를 추출하고 싶다면 대상의 특징을 잘 표현할 수 있어야 한다. 컴퓨터이기 때문에 각 특징은 당연히 수치로 표현되며, 계산된 특징으로 최대한 많은 데이터를 설명할 수 있어야 한다.
이 포스트에서는 단어에 대한 특징 추출 방법 중 하나인 TF-IDF를 알아볼 것이다. TF-IDF TF-IDF은 텍스트 마이닝(Text Mining)에서 많이 사용된다.
TF-IDF는 출현 빈도를 사용해서 어떤 단어 w 가 문서 d 내에서 얼마나 중요한지를 나타내는 수치이다. 이 수치가 높으면 높을 수록 w 는 d 를 대표한다고 볼 수 있다.
TF는 term-frequency의 약자이며, 단어의 문서 내 출현 횟수를 의미한다. IDF는 Inverse document frequency의 약자이며, 그 단어가 출현한 문서 개수의 역수를 의미한다.
"단어가 문서에 출현한 횟수가 많으면 많을...
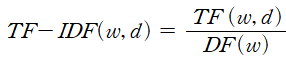
원문 링크 : (데이터 전처리) TF-IDF Embedding