
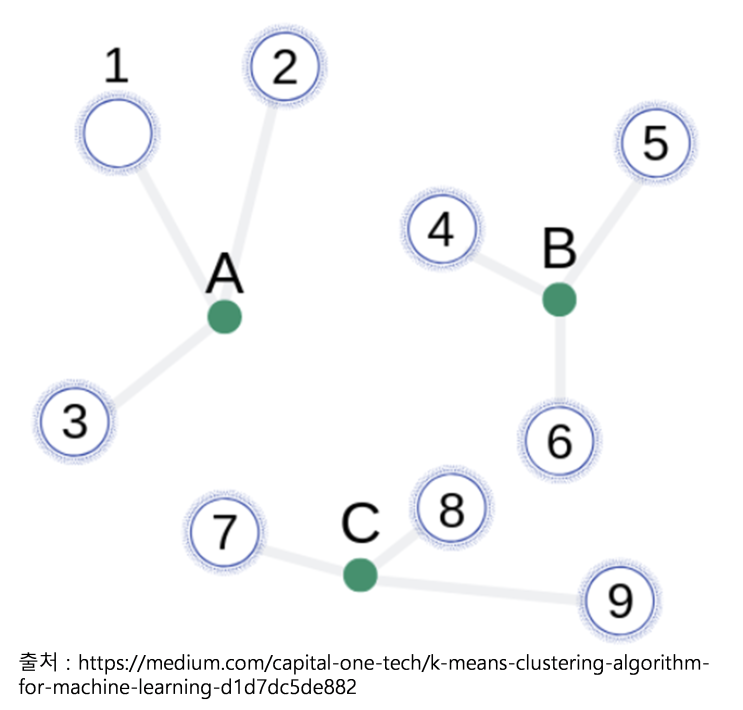
K-means Clustering Algorithm 머신러닝에서 비지도 학습의 기법의 하나며, 데이터 세트에서 서로 유사한 관찰치 들을 그룹으로 묶어 분류하여 몇 가지의 군집(cluster)을 찾아내는 것 기법이다. 어떤 데이터 세트가 있고 k개의 클러스터로 분류하겠다고 가정하면, 그 데이터 세트에는 k개의 중심(centroid)이 존재한다.
각 데이터는 유클리드 거리를 기반으로 가까운 중심에 할당되고, 같은 중심에 모인 데이터 그룹이 하나의 클러스터가 된다. 그런 다음 시간이 지남에 따라 더 정확한 분류를 수행하기 위해 이 기술을 반복한다.
이때 Mean(평균)은 각 클러스터의 중심과 주변에 모인 데이터들의 평균 거리가 된다. 설명을 다시 주요 3단계로 나눠 살펴보면, 1단계 : 데이터를 이해하고 가장 의미 있는 k 값을 선택 2단계 : 둘째, 각 데이터를 인근 군집에 할당하여 k개의 군집을 생성 3단계 : 수렴 기준에 도달할 때까지 이전 단계를 반복해야 한다.
중심 값이 더는 변...
#
Kmeans
#
KmeansClustering
#
K평균
#
머신러닝
#
비지도학습
#
인공지능
